Speech-activated systems have recently taken over the show, from in-car navigation to interactive VAs. However, for these inventive and autonomous setups to perform accurately and efficiently, they must be fed data that has been sectioned, segmented, and curated.
While audio/speech data collection ensures insight availability, blindly feeding datasets will only help the models if given context.
This is where Subul’s audio/speech labeling or annotation comes into play; we ensure that previously collected datasets are perfectly labeled and capable of handling specific use cases like voice assistance, navigation support, translation, and more.
In a basic sense, audio/ speech annotation for NLP is labeling recordings in a format that machine learning setups can recognize.
For example, for voice assistants like Cortana and Siri to understand the context of our queries, emotions, sentiments, semantics, and other nuances, they were initially fed massive amounts of annotated audio.
Audio Annotation Services by Subul – Custom Audio Annotation isn’t a Distant Dream Anymore
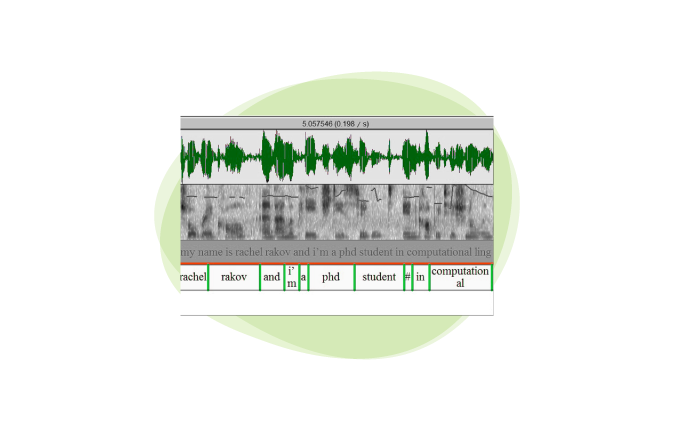
Subul has always excelled at providing speech and audio labeling services. With our cutting-edge audio and speech labeling solutions, we develop, train, and improve conversational AI, chatbots, and speech recognition engines.
Hours of multilingual audio can be gathered by our global network of qualified linguists, who work with an accomplished project management team to annotate vast amounts of data for voice-enabled application training.
We also transcribe audio files to extract meaningful insights from audio formats. Now, select the audio and speech labeling technique that best meets your needs and leave the brainstorming and technicalities to Subul.
Audio Transcription
Incorporating truckloads of meticulously transcribed speech and audio data creates intelligent NLP models. At Subul, we give you a more comprehensive range of options, such as standard audio, verbatim transcription, and multilingual transcription. Additionally, you can train the models using more time stamping and speaker identification information.
Speech Labeling
As a common annotation technique, speech or audio labeling involves dividing sounds and labeling them with particular metadata. The core of this method entails ontologically identifying sounds from a piece of audio and accurately annotating them to broaden the scope of the training datasets.
Audio Classification
Speech annotation companies use it to train AIs to perfection when analyzing audio recordings based on the content. As part of a more proactive training regime, machines can identify voices and sounds while distinguishing between the two using audio classifications.
Multilingual Audio Data Services
Collecting multilingual audio data is only useful if the annotators can label and segment it appropriately. This is where multilingual audio data services come in handy, as they are concerned with annotating speech based on the diversity of the language so that it can be perfectly identified and parsed by the relevant AIs.
Natural Language Utterance
NLU annotates human speech to classify the smallest details, such as semantics, dialects, context, stress, etc. This type of annotated data is useful for improving the training of virtual assistants and chatbots.
Multi-Label Annotation
Annotating audio data with multiple labels is necessary to assist models in distinguishing overlapping audio sources. An audio dataset may belong to one or more classes in this approach, which must be explicitly conveyed to the model for better decision-making.
Phonetic Transcription
Unlike regular transcription, which converts audio into a sequence of words, phonetic transcription notes how words are pronounced and visually represents the sounds using phonetic symbols. As a result, phonetic transcription makes distinguishing between dialects of the same language easier.
Subul enters the picture by making cutting-edge datasets available for training AI and ML setups by standard use cases.
You don’t have to second-guess model ideation when you have us on your side because our professional workforce and a team of expert annotators are always on the job labeling and categorizing speech data in relevant repositories.